

En tant que MSP, la surveillance et les alertes sont au cœur des services que vous fournissez. Les bonnes pratiques de surveillance vous permettent d’identifier de manière proactive les problèmes, de les résoudre plus rapidement et d’être plus efficace. Une meilleure surveillance peut également jouer un rôle clé dans la génération de revenus supplémentaires et la satisfaction de vos clients.
Le défi est de savoir ce qu’il faut surveiller, ce qui nécessite une alerte, quels problèmes peuvent être résolus automatiquement et lesquels nécessitent une touche personnelle. Ces connaissances peuvent prendre des années à se développer et, même dans ce cas, les meilleures équipes peuvent encore lutter pour réduire la fatigue des alertes et le bruit des tickets sur les appareils clients.
Pour aider les débutants à condenser ce temps de montée en puissance et à affiner leur objectif, nous avons rassemblé cette liste d’idées pour plus de 25 conditions à surveiller. Ces recommandations sont basées sur les suggestions de nos partenaires et sur l’expérience de NinjaOne dans l’aide de MSP à mettre en place un suivi efficace et exploitable.
Comment utiliser les listes de contrôle ci-dessous
Pour chaque condition, nous décrivons ce qui est surveillé, comment configurer le moniteur dans NinjaOne et quelles actions doivent être entreprises si la condition est déclenchée. Certaines suggestions de surveillance sont concrètes tandis que d’autres peuvent nécessiter une petite quantité de personnalisation pour les adapter à votre cas d’utilisation.
Remarque : bien que nous ayons rédigé cette liste de contrôle en pensant à NinjaOne et à nos clients, ces idées de surveillance devraient être facilement adaptables à n’importe quel RMM.
Cette liste n’est évidemment pas exhaustive et peut ne pas s’appliquer à toutes les situations ou circonstances.
Une fois que vous avez commencé à développer votre surveillance autour de ces suggestions, vous devrez développer une stratégie de surveillance plus personnalisée et plus robuste, spécifique à vos clients et à leurs besoins. Nous clôturerons cet article avec des recommandations supplémentaires pour vous aider dans cet effort et faire de la surveillance, des alertes et de la génération de tickets un avantage concurrentiel pour votre MSP.
Liste de contrôle pour la surveillance de l’état de santé des appareils

Surveiller les événements critiques continus
- Condition : événements critiques
- Seuil : 80 événements critiques en 5 minutes
- Action : ticket et enquête
Identifier quand un appareil est redémarré involontairement
- Condition : événement Windows
- Source de l’événement : Microsoft-Windows-Kernel-Power
- ID d’événement : 41
- Remarque : cette condition est mieux adaptée aux serveurs car les postes de travail et les ordinateurs portables peuvent créer cette erreur suite à l’intervention de l’utilisateur.
- Action : ticket et enquête
Identifier les appareils nécessitant un redémarrage
- Condition : temps de disponibilité du système
- Seuil de recommandation : 30 ou 60 jours
- Action : redémarrez l’appareil pendant une fenêtre appropriée. La correction automatisée peut fonctionner pour les postes de travail.
Surveiller les terminaux hors ligne
- Condition : appareil en panne
- Recommandation de seuil :
- 10 minutes ou moins (serveurs)
- Plus de 24 heures (postes de travail)
- Action :
- Ticket et enquête
- Réveil-sur-lan (serveurs uniquement)
Surveiller les changements matériels
- Activité : système
- Nom : adaptateur ajouté / modifié, processeur ajouté / retiré, disque dur ajouté / retiré, mémoire ajoutée / retirée
- Action : ticket et enquête
Liste de contrôle pour la surveillance des disques
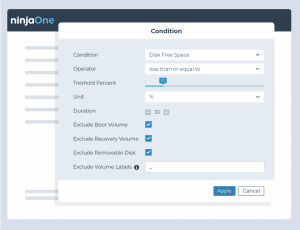
Surveiller les pannes potentielles de disques
- Condition :statut SMART de Windows dégradé
et/ou - Condition : événement Windows
- Source de l’événement : disque
- ID d’événement : 7, 11, 29, 41, 51, 153
- Action : ticket et enquête
Identifier quand l’espace disque approche de sa capacité maximale
- Condition : espace libre sur le disque
- Seuil : 20 % et encore à 10 %
- Action : effectuez le nettoyage du disque et supprimez les fichiers temporaires
Surveiller les pannes RAID potentielles
- Condition : état de santé du RAID
- Seuils : critiques et non critiques pour tous les attributs
- Action : ticket et enquête
Surveiller une utilisation prolongée du disque
- Condition : utilisation du disque
- Seuils : 90 % ou plus pour réduire le bruit, plus de 95 % étant également courant sur des périodes de 30 ou 60 minutes
- Action : ticket et enquête
Surveiller le taux d’activité élevé du disque
- Condition : temps actif du disque
- Seuils : supérieurs à 90 % pendant 15 minutes
- Action : ticket et enquête
Surveiller une utilisation élevée de la mémoire
- Condition : temps actif du disque
- Seuils : supérieurs à 90 % pendant 15 minutes
- Action : ticket et enquête

Liste de contrôle pour la surveillance des applications
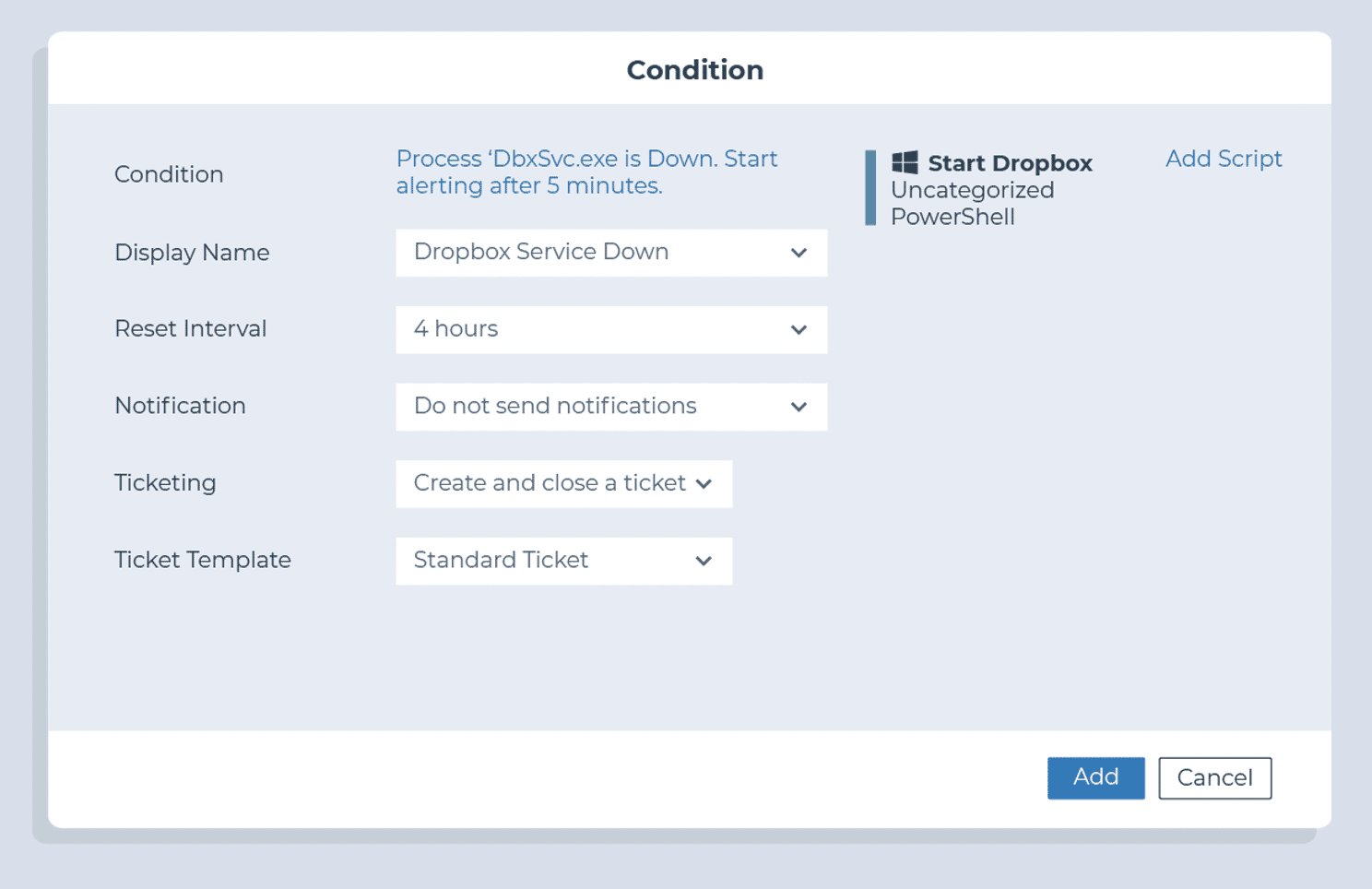
Identifier si les applications requises existent sur un terminal
- Condition : logiciel
- Utilisation :
- Applications métier client (exemples : AutoCAD, SAP, Photoshop)
- Solutions de productivité client (exemples : Zoom, Microsoft Teams, DropBox, Slack, Office, Acrobat)
- Outils de support client (exemples : TeamViewer, CCleaner, AutoElevate, BleachBit)
- Action : installez automatiquement l’application si elle est manquante et requise
Surveiller si les applications critiques sont en cours d’exécution (en particulier pour les serveurs)
- Condition : processus / service
- Seuil : en panne pendant au moins 3 minutes
- Exemples de processus :
- Pour les postes de travail : TeamViewer, RDP, DLP
- Pour un serveur Exchange : MSExchangeServiceHost, MSExchangeIMAP4, MSExchangePOP3, etc.
- Pour un serveur Active Directory : Netlogon, dnscache, rpcss, etc.
- Pour un serveur SQL : mssqlserver, sqlbrowser, sqlwriter, etc.
- Action : redémarrez le service ou le processus
Surveiller l’utilisation des ressources pour les applications connues pour causer des problèmes de performances
- Condition : ressource de processus
- Seuil : supérieur à 90 % pendant au moins 5 minutes
- Exemples de processus : Outlook, Chrome et TeamViewer
- Action :
- Ticket et enquête
- Désactiver au démarrage
Surveiller les plantages d’application
- Condition : événement Windows
- Source : blocage d’applications
- ID d’événement : 1002
- Action : ticket et enquête
Liste de contrôle de la surveillance des réseaux

Surveiller l’utilisation inattendue de la bande passante
- Condition : utilisation du réseau
- Direction : extérieure
- Seuil : les seuils seront déterminés par le type de terminal et la capacité du réseau
- Chaque serveur doit avoir son propre seuil en fonction de son cas d’utilisation
- Les seuils de surveillance du réseau du poste de travail doivent être suffisamment élevés pour se déclencher uniquement lorsque le réseau d’un client est à risque
- Action : ticket et enquête
Assurez-vous que les périphériques réseau sont en place
- Condition : appareil en panne
- Durée : 3 minutes
Surveillez les ports ouverts
- Condition : surveillance du cloud
- Ports : 80 (HTTP), 443 (HTTPS), 25 (SMTP), 21 (FTP)
Surveiller la disponibilité du site Internet du client
- Surveillance : Ping
- Cible : site Internet du client
- Condition : défaillance (5 fois)
- Action : ticket et enquête
Liste de contrôle de base de la surveillance de la sécurité
Identifier si le pare-feu Windows a été désactivé
- Condition : événement Windows
- Source de l’événement : système
- ID d’événement : 5025
- Action : activez le pare-feu Windows
Identifier si les outils antivirus et de sécurité sont installés et/ou en cours d’exécution sur un terminal
- Condition : logiciel
- Présence : n’existe pas
- Logiciel (exemples) : Huntress, Cylance, Threatlocker, Sophos
- Action : Automatisez l’installation du logiciel de sécurité manquantet
- Condition : processus / service
- État : en panne
- Processus (exemples) : menacelockerservice.exe, EPUpdateService.exe
- Action : redémarrez le processus
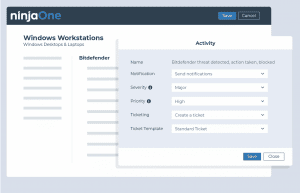
Surveiller les menaces AV / EDR non intégrées détectées
- Condition : événement Windows
- Exemple (Sophos)
- Source de l’événement : antivurs Sophos
- ID d’événement : 6, 16, 32, 42
Surveiller les tentatives de connexion des utilisateurs ayant échoué
- Condition : erreur Windows
- Source de l’événement : Microsoft-Windows-Security-Auditing
- ID d’événement : 4625, 4740, 644 (comptes locaux) ; 4777 (connexion au domaine)
- Action : ticket et enquête
Surveiller la création, l’élévation ou la suppression d’utilisateurs sur un terminal
- Condition : erreur Windows
- Source de l’événement : Microsoft-Windows-Security-Auditing
- ID d’événement : 4720, 4732, 4729
- Action : ticket et enquête
Identifier si les lecteurs sur un terminal sont chiffrés/non chiffrés
- Condition : résultat du script
- Script (personnalisé) : vérifier l’état du chiffrement
- Action : ticket et enquête
Surveiller les échecs de sauvegarde (Ninja Data Protection)
- Activité : Ninja Data Protection
- Nom : la tâche de sauvegarde a échoué
Surveiller les échecs de sauvegarde (autres fournisseurs de sauvegarde)
- Condition : événement Windows
- Exemple de source / ID (Veeam) :
- Source de l’événement : agent Veeam
- ID d’événement : 190
- Le texte contient : échec
- Exemple de source / ID (Acronis) :
- Source de l’événement : système de sauvegarde en ligne
- ID d’événement : 1
- Le texte contient : échec
4 points clés pour améliorer votre surveillance
- Créez un modèle de surveillance de l’état des appareils de base.
- Parlez aux clients de leurs priorités.
- Quels serveurs et postes de travail sont importants ?
- Quels sont leurs domaines d’activité ou leurs applications de productivité critiques ?
- Où sont leurs problèmes informatiques ?
- Surveillez votre PSA / système de création de ticket pour les problèmes récurrents.
- Ajustez les alertes pour éviter le bruit des tickets.
- Surveillez les journaux d’événements des clients pour les problèmes récurrents.
Bonnes pratiques de création de ticket et des alertes
- Alerte uniquement sur les informations exploitables. Si vous n’avez pas de réponse spécifique associée à un moniteur, ne le surveillez pas.
- Catégorisez vos alertes pour aller à différents tableaux de service dans votre PSA en fonction du type ou de la priorité.
- Organisez régulièrement des réunions de gestion des alertes pour discuter de :
- Quelles alertes génèrent le plus de bruit ? Peuvent-elles être supprimées ou restreintes ?
- Qu’est-ce qui n’est pas surveillé ou ne crée pas de notifications qui devraient l’être ?
- Quelles alertes courantes peuvent être automatiquement corrigées ?
- Y a-t-il un projet à venir qui pourrait générer des alertes ?
- Nettoyez vos tickets et alertes lorsqu’ils sont résolus.
- Dans NinjaOne, de nombreuses conditions ont un « Réinitialiser quand ce n’est plus vrai » ou « Réinitialiser quand ce n’est pas vrai pendant x période » pour vous aider à résoudre et à nettoyer les notifications qui peuvent se résoudre d’elles-mêmes.
Vous recherchez plus d’idées de surveillance ?
Voir l’excellente série de Kelvin Tegelaar (en anglais) sur la surveillance à distance à l’aide de PowerShell. Elle explique comment tout surveiller, du trafic réseau à l’intégrité d’Active Directory en passant par les échecs de connexion Office 365, les résultats Shodan, etc. Mieux encore, il partage des scripts PowerShell conçus pour être indépendants de RMM. Vous pouvez également lire notre article de blog sur les différences entre PowerShell et CMD Prompt (en anglais) et quand les utiliser.
Nous présentons régulièrement ses articles de blog ainsi que de nombreux outils et ressources supplémentaires dans notre newsletter hebdomadaire MSP Bento (en anglais). Abonnez-vous maintenant pour obtenir la dernière édition ainsi qu’une liste spéciale des outils et ressources les plus populaires que nous avons partagés.






